StreamFinetuner
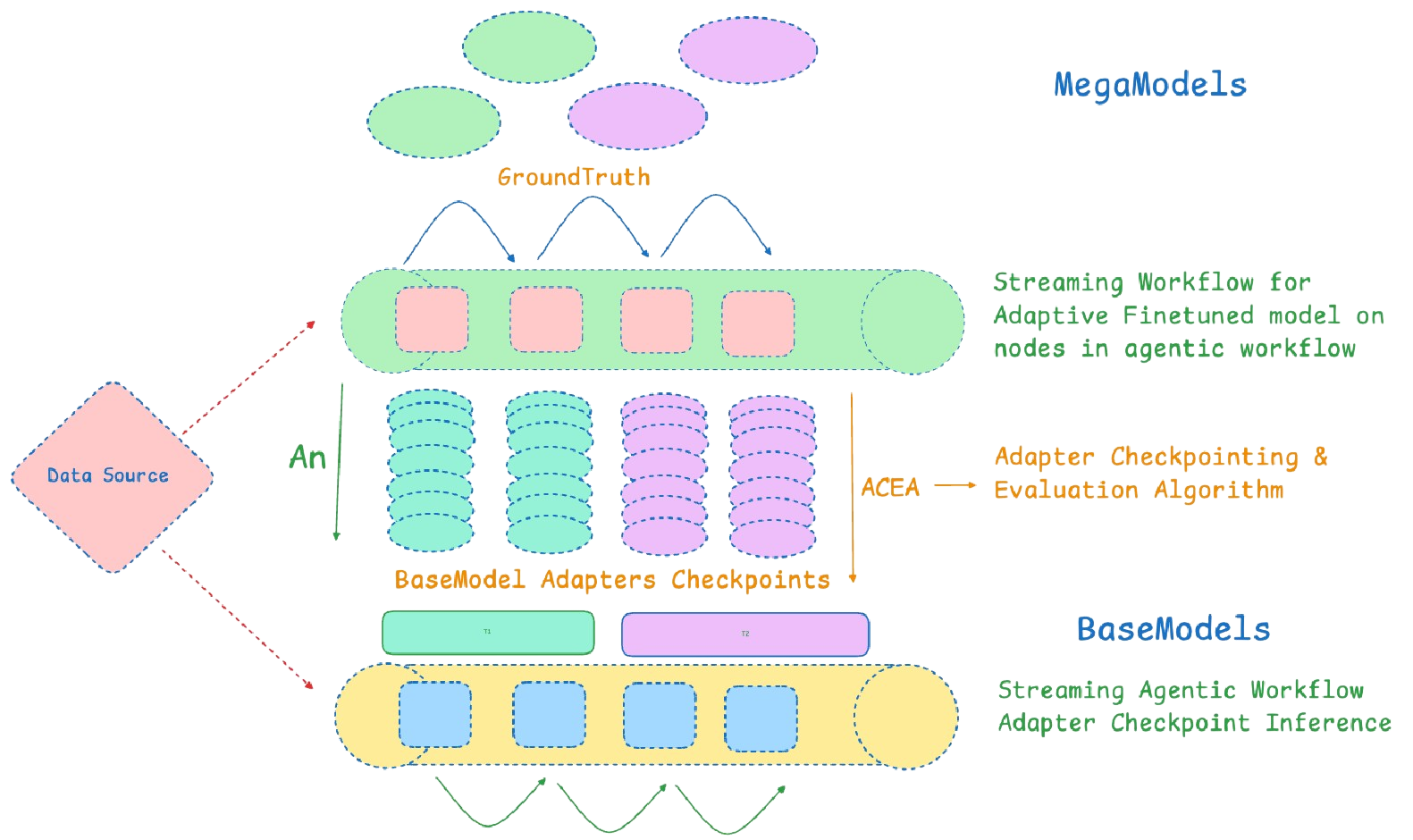
The StreamFinetuner in Nstream AI is a real-time model fine-tuning component that continuously adapts AI models using streaming data, ensuring they evolve with dynamic patterns and context. By leveraging a KnowledgeBase for contextual retrieval, it enhances model accuracy and relevance, making it ideal for high-throughput AI-driven workflows like retrieval-augmented generation (RAG), fraud detection, and market intelligence. Designed for seamless deployment in a Kubernetes-native environment, StreamFinetuner enables AI models to learn from live data, improving real-time inference and decision-making for streaming applications.
Sample YAML Configuration
apiVersion: llm.nstream.ai/v1
kind: StreamFinetuner
metadata:
name: "STREAMFINETUNER_NAME"
namespace: "NAMESPACE"
spec:
finetunerInfo:
baseModel: "BASE_MODEL"
dataSource:
sourceStreamConnector: "SOURCE_FINETUNE_CONNECTOR"
sourceStreamFinetuner: "OPTIONAL_STREAM_FINETUNER"
knowledgeBase: "KNOWLEDGEBASE_NAME"
megaModel: "MEGAMODEL_NAME"
finetunerTemplate:
dataProcessorTemplate:
checkpointingInterval: "CHECKPOINT_INTERVAL"
flinkMemorySize: "FLINK_MEMORY"
managedMemorySize: "MANAGED_MEMORY"
parallelism: PARALLELISM_LEVEL
processMemorySize: "PROCESS_MEMORY"
finetunerResources:
limits:
cpu: "CPU_LIMIT"
gpu: "GPU_LIMIT"
memory: "MEMORY_LIMIT"
requests:
cpu: "CPU_REQUEST"
gpu: "GPU_REQUEST"
memory: "MEMORY_REQUEST"
preProcessing:
knowledgeSearchLimit: KNOWLEDGE_SEARCH_LIMIT
preProcessingSQL: "PREPROCESSING_SQL_QUERY"
sampleRatio: "SAMPLE_RATIO"
ioSequenceLength:
inputMax: "INPUT_MAX_LENGTH"
outputMax: "OUTPUT_MAX_LENGTH"
promptTemplate:
- systemContext: "SYSTEM_CONTEXT"
userQuestion: "USER_QUESTION"
trainer:
batchSize: "BATCH_SIZE"
epochs: "EPOCHS"
gradientAccumulationSteps: "GRADIENT_ACCUMULATION_STEPS"
learningRate: "LEARNING_RATE"
useMixedPrecision: "MIXED_PRECISION"
YAML Configuration Parameters
| Key | Description | Example |
|---|---|---|
apiVersion | Defines the API version for the configuration | llm.nstream.ai/v1 |
kind | Identifies the type of resource being configured | StreamFinetuner |
name | Unique name for the StreamFinetuner instance | node-1-finetuner |
namespace | Kubernetes namespace where the instance is deployed | default |
baseModel | Base language model to be fine-tuned | llama3-8b-instruct |
dataSource.sourceStreamConnector | Connector for the source stream data | event-source-connector |
knowledgeBase | Reference to the associated KnowledgeBase | node-1-kb |
megaModel | Reference to a mega model used to generate grounded responses | azure-openai-4o |
checkpointingInterval | Interval for data checkpointing | 5m |
flinkMemorySize | Memory allocated to Flink processes | 8192m |
cpu | CPU resource limit for the finetuning process | 8000m |
preProcessingSQL | SQL query for preprocessing the input data | SELECT * FROM source_stream WHERE event_time >= now() - interval '1 day'; |
systemContext | Context provided to the model for generating responses | "You are a Financial Analyst with specialized expertise in interpreting Open-High-Low-Close (OHLC) data." |
WlearningRate | Learning rate for model training | 0.00005 |